VPR_processing
Emily O’Grady, Kevin Sorochan, Catherine Johnson
VPR_processing.RmdSection 1: Background
This document was produced at Bedford Institute of Oceanography (BIO) to accompany the vprr package, a processing and visualization package for data obtained from the Digital Auto Video Plankton Recorder (VPR) produced by SeaScan Inc. The VPR consists of a CPU, CTD, and camera system with different optical settings (i.e., magnifications). It captures underwater images and records their corresponding salinity, temperature, and depth. The vprr package functions to join environmental and plankton data derived from the CTD and camera, respectively, and calculate plankton concentration and averaged environmental variables along the path of the VPR. The package does not include automated image classification; however, there is an optional manual classification module, which can be used to review and correct outputs from automated image classification while providing a record of any (re)classifications. The VPR outputs two raw files (.dat and .idx) for a given time period in a deployment. These files are processed together in a software provided with the VPR (i.e., AutoDeck), which decompresses the images, extracts “regions of interest” (ROIs), and outputs ROI image files and a corresponding CTD data file (.dat). The ROI file names are numeric consisting of 10 digits. The first 8 digits correspond to the number of milliseconds elapsed in the day at the time the image was captured. The last two digits correspond to the ROI identifier (01-99). In each deployment, the ROIs and corresponding CTD data are linked by their 8 digit time stamp. After the ROIs have been extracted from the raw files they may be sorted into categories. In vprr, file naming conventions and directory structures are inherited from a previously available VPR image classification and analysis software (i.e., Visual Plankton). The functionality of vprr is not dependent on Visual Plankton. The data inputs for processing in vprr consist of the following file types: aid (.txt), aidmeas (.txt), and CTD (.dat). The aid and aidmeas files are derived from separate image classification and measurement steps outside of vprr. Each “aid” (i.e., autoid) file contains file paths to individual ROIs that have been classified to the category of interest. The corresponding “aidmeas” file contains morphological data for the ROIs (e.g., long axis length) that can be obtained from software external to vprr. These morphological data are not required for sorting images or computing plankton concentrations in vprr.
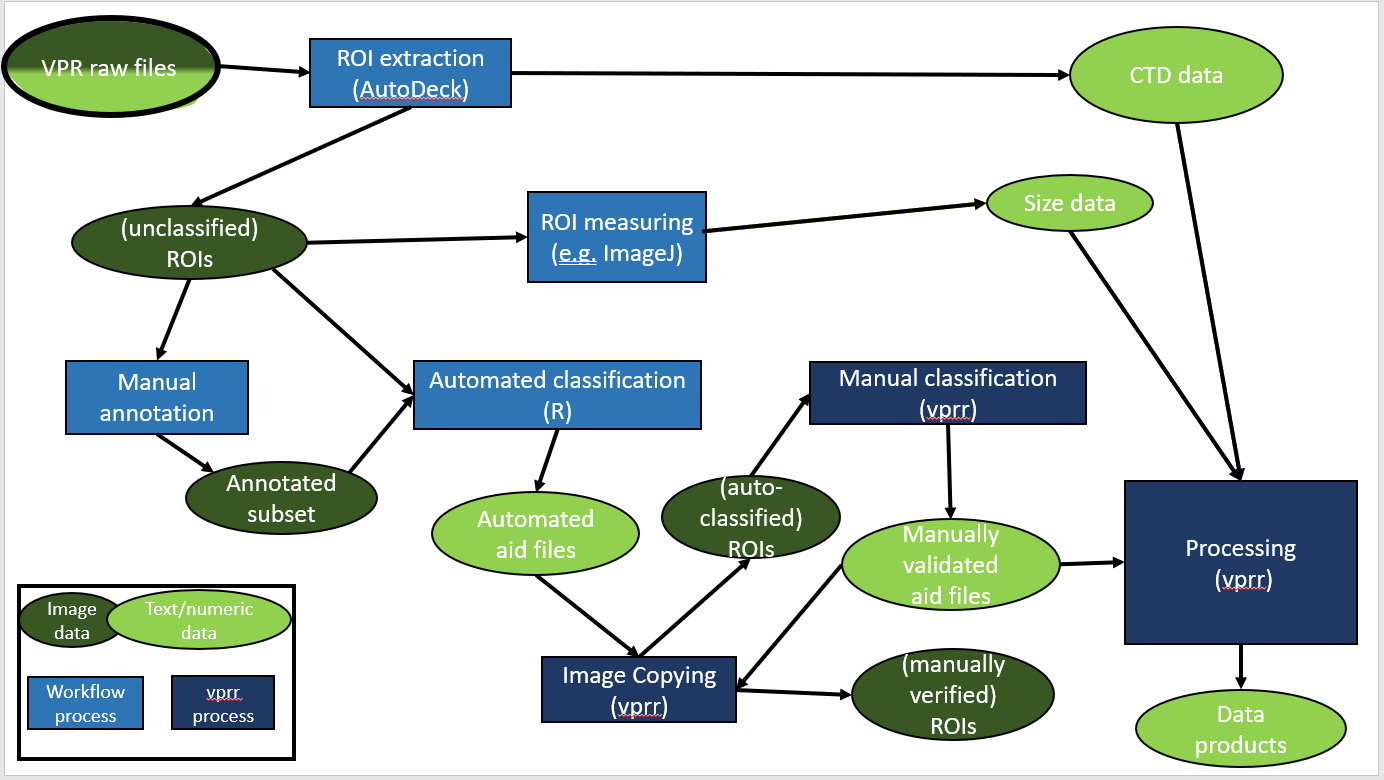
Section 2: Summary of vprr data processing steps
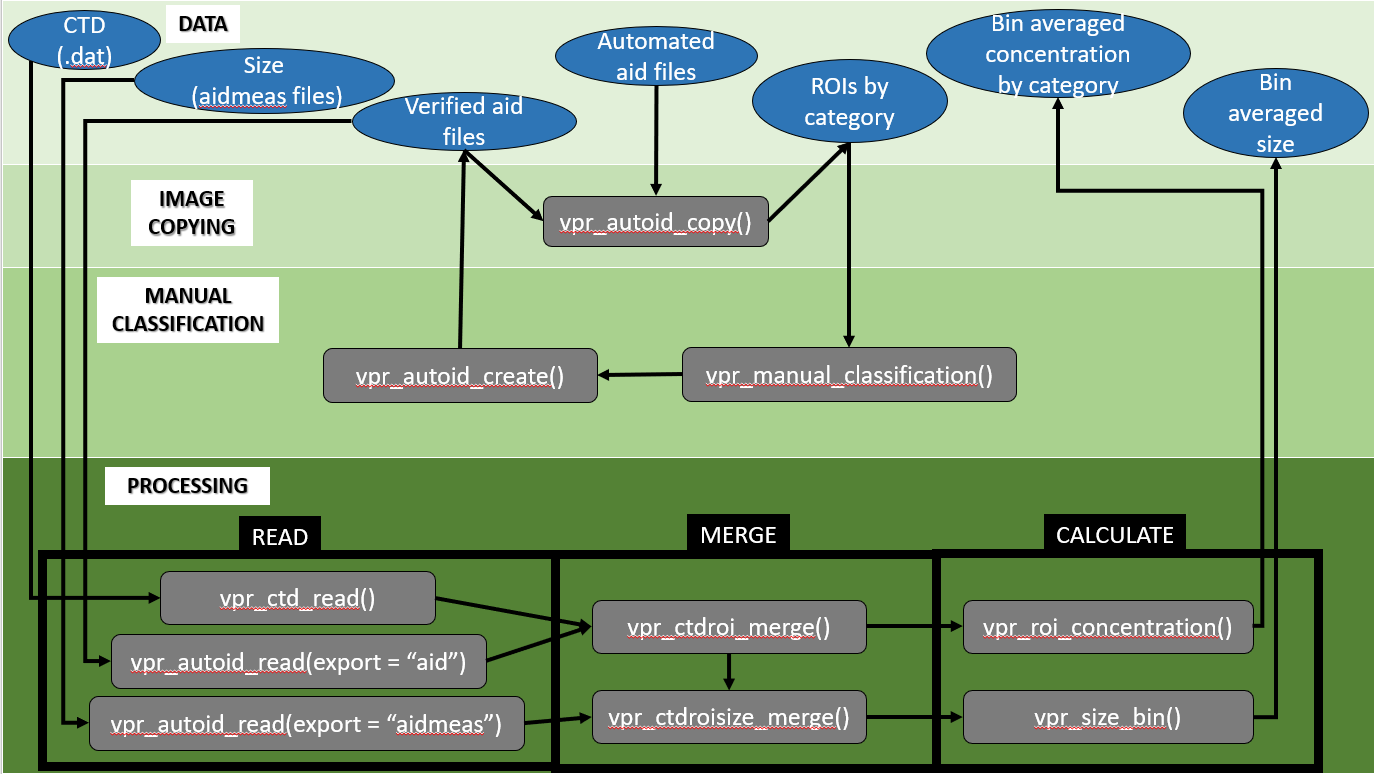
The processing steps performed in vprr are detailed in Figure 2, along with the associated data outputs.
Processing Environment
Before beginning data processing with vprr, it is recommended that a processing environment be created containing commonly used variables and file paths. The simplest and most reproducible way to achieve this is to write an R script where all the mission and system specific variables are contained, then save the environment as a RData file to be loaded at the start of any processing scripts. The processing environment in the example below links a station identifier to the day and hour values assigned by AutoDeck. Day and hour values represent the Julian day (3 digit) and two digit hour (24 hour clock) when sampling was done. Note that the day and hour values will be in the time zone of the computer used to run AutoDeck. Ensure that this matches the time zone of the VPR CPU at the time of data collection to avoid a time offset between data sources.
Another important part of setting up the processing environment is ensuring the proper directory structure is in place, see Appendix 1 for details on the required directory structure.
#### set VPR processing environment --------------------------------------
# setwd('~/COR2019002/')
day <- c('222', '222') # 3 digits
hr <- c('03', '04') # 2 digits
cast <- '5' # chr
station <- 'Example' # chr
cruise <- 'COR2019002' # chr
opticalSetting <- 'S2' # chr
dh <- paste0('d', day, '.h', hr)
station_of_interest <- paste0('vpr', cast, '_', station)
binSize <- 3 # num (metres)
imageVolume <- 41439 # num
year <- '2019' # chr
# location for new autoid folder
new_autoid <- 'new_autoid/'
# location of original ROIs
roi_path <- 'extdata/'
# location of CNN aid files
manual_class_basepath <- 'extdata/COR2019002/autoid'
# location of manual classification records
manual_record_path <- 'extdata/COR2019002/manual_reclassification_record/'
# location of CTD data
castdir <- 'extdata/COR2019002/rois/vpr5/d222'
# get categories
categories <- list.files(new_autoid, include.dirs = TRUE)
# Save processing environment
# save.image(file = paste0(cruise, "env.RData"))Once this environment is set, it can be loaded into any processing session by using
load('COR2019002_env.RData') # where COR2019002 is cruise nameImage Copying (optional):
ROIs are organized into folders corresponding to their assigned classification categories from automated image classification. The information in each aid file is used to create a folder of images that have been classified to that category. This step is only required if manual re-classification (see Section 2.2) is intended. Further details on image copying are provided in Section 3.
Manual re-classification (optional):
Automated classifications are manually checked, which allows for manual correction and addition of categories not previously used for automated classification. ROIs that have been copied are manually sorted to correct for misclassifications. Updated aid and aidmeas files are produced. Further details on manual re-classification are provided in Section 4.
Data Processing:
Data outputs including CTD (.dat files), automated classifications (aid files) and measurements (aidmeas files) are joined together. For each deployment, the aid and aidmeas files, which may have been updated, are joined with CTD text files by the 8 digit time stamp (ROI number). The data are then averaged in user-defined vertical bins to produce a time series of plankton concentrations and environmental variables. Data products (before and after binning) can then exported in simple formats (e.g., csv, RData, oce) for plotting and analysis. Further details on data processing are provided in Section 5.
Section 3: Image Copying
In this step, ROIs are copied to folders that are organized based on
the day and hour of data collection and classification category assigned
from automated classification (see Appendix 1: ‘Image Folders’). The
images are organized by AutoDeck into day and hour; however,
reorganizing them based on classification allows easier human
interaction with the data and visual inspection of classifications.
Moreover, this directory structure is used by the next step of
processing (i.e., manual re-classification). To implement this step use
the function vprr::vpr_autoid_copy() For more information
on input variables, please see documentation for
vpr_autoid_copy()
#### run image organization -----------------------------------------------
vpr_autoid_copy(new_autoid = new_autoid,
roi_path = roi_path,
day = day,
hour = hr,
cast = cast,
station = station,
threshold = NULL,
org = 'dayhour'
)Section 4: Manual Re-classification
Manual re-classification of some categories after automated classification may be required to achieve identification accuracy standards. In this step, ROIs are displayed on the screen one at a time for manual verification. If an image has been misclassified or if it falls into a new user-defined category (described below), the image can be re-classified. This is especially useful for classification of rare categories that were not defined prior to automated classification. After completing manual re-classification for a day-hour set, new aid and aidmeas files are created in a separate folder for the categories, which are identical in format to original aid and aidmeas files.
Section 4.1: Preparing the environment by setting some variables
Load the processing environment, which includes the
basepathvariable.Set day and hour of interest.
Set the categories for manual classification. These categories are the existing automated classification categories which require manual re-classification, as well as any new categories. The
vprr::vpr_category_create()function sets up the folder structure for any new categories which have been added to the list of interest.Note that if you create new categories part way through manual classification, no misclassified files will have been created in this category for hours which you have already processed. This may cause some unexpected errors down the line in processing, you could either reprocess previous hours of data with all the new categories or manually create empty “misclassified files” (see below).
Run manual re-classification with
vprr::vpr_manual_classification(). This function has a few optional arguments to customize the manual re-classification experience, notablygrwhich is a logical value determining whether or not manual re-classification options appear as pop ups or in the console, as well asimg_bright, a logical which determines whether or not the original image is appended with a bright version of the image. Having a bright version of the image allows the user to see the outline of the organism better; thin appendages become more clear, and gelatinous organisms may be easier to distinguish.-
If the output from automated classification includes a probability score for each ROI, the threshold argument in vpr_manual_classification() can be used to determine the minimum automated classification confidence required for images to be passed through without manual verification.
#### MANUAL RE-CLASSIFICATION ------------------------------------- # Once automated classification is complete # verify classification accuracy by manually # looking through select images load('COR2019002_env.RData') # category_new <- # c( # "veliger_gastropod" # ) # # add new category # vprr::vpr_category_create(taxa = category_new, basepath = auto_id_folder) vpr_manual_classification(day = day, hour = hr, basepath = manual_class_basepath, gr = FALSE)
Section 4.2: Generate new aid and aidmeas files
The function vprr::vpr_manual_classification() produces
two files (‘misclassified’ and ‘re-classified’ text files) as a record
of manual re-classification. These files are stored in the R project
working directory in a folder named “manual_reclassification_record”
with subfolders named by the day and hour that the data were collected.
The function vprr::vpr_autoid_create() takes these files
and outputs new aid and aidmeas files in the R working directory in a
folder named “new_autoid” with sub folders named by classification
category. This step should be run after each hour of data is manually
re-classified. If aidmeas files have not been created (through a
separate measurement workflow), these functions will run on just the aid
files without issue.
#### REORGANIZE ROI AND ROIMEAS DATA ---------------------------------------
# get mis/re classified files
manual_record <- list.files(file.path(manual_record_path, dh),
full.names = TRUE)
misclassified <- grep(manual_record,
pattern = "misclassified",
value = TRUE)
reclassify <- grep(manual_record, pattern = "reclassify", value = TRUE)
# MOVE ROIS THAT WERE MISCLASSIFIED INTO CORRECT FILES & REMOVE MISCLASSIFIED ROIS
vpr_autoid_create(reclassify, misclassified, manual_class_basepath,
mea = FALSE, categories = categories)The aid and aidmeas files are specifically formatted to record classification outputs for further processing. The aid files are text records of image paths, where each individual text file represents a classification category. Each line of the aid file is the full path to an image which was classified into the designated category. Note that the naming scheme of aid files does not include the category name in the file title and the category is only identifiable by the folder in which it is located. For example, a ‘krill’ classification aid file might be named ‘sep20_2svmaid.d222.h03’ and located within the ‘krill’ autoid folder (see example below). The aidmeas files are also text files which represent a variety of different measurements taken of the object(s) within a ROI image. The columns of the aidmeas files are c(‘Perimeter’, ‘Area’, ‘width1’, ‘width2’, ‘width3’, ‘short_axis_length’, ‘long_axis_length’). The aidmeas files are not created or required for processing with vprr. Examples of each of these files can be found below.
aid <- read.table(file = system.file("extdata/COR2019002/autoid/krill/aid/sep20_2svmaid.d222.h03",
package = 'vprr', mustWork = TRUE))
head(aid)
#> V1
#> 1 c:\\data\\cruise_COR2019002\\rois\\vpr5\\d222\\h03\\roi.2248682400.tif
#> 2 c:\\data\\cruise_COR2019002\\rois\\vpr5\\d222\\h03\\roi.2250029400.tif
#> 3 c:\\data\\cruise_COR2019002\\rois\\vpr5\\d222\\h03\\roi.2250197100.tif
#> 4 c:\\data\\cruise_COR2019002\\rois\\vpr5\\d222\\h03\\roi.2250252500.tif
#> 5 c:\\data\\cruise_COR2019002\\rois\\vpr5\\d222\\h03\\roi.2253587400.tif
#> 6 c:\\data\\cruise_COR2019002\\rois\\vpr5\\d222\\h03\\roi.2254200600.tif
aidmeas <- readLines(
system.file("extdata/COR2019002/autoid/krill/aidmea/sep20_2svmaid.mea.d222.h03",
package = 'vprr', mustWork = TRUE))
head(aidmeas)
#> [1] " 964.99 8534.00 39.92 53.85 78.55 117.57 275.20"
#> [2] " 637.57 6857.00 38.90 42.72 28.79 47.79 229.32"
#> [3] " 373.38 1183.00 4.12 4.12 15.03 22.00 119.75"
#> [4] " 290.11 2910.00 27.66 30.81 19.24 35.49 114.73"
#> [5] " 660.80 6071.00 35.90 46.87 27.89 60.44 157.69"
#> [6] " 204.12 1162.00 9.22 10.20 12.04 17.41 88.34"Section 4.3: File check
The last step of manual re-classification includes some manual file
organization and final checks. The function
vprr::vpr_autoid_check() produces a summary file in the
working directory that indicates whether or not ROIs are duplicated or
missing. It is recommended that the user also manually check some of the
files to verify correct functionality.
#### FILE CHECK ----------------------------------------------------------
vpr_autoid_check(new_autoid, original_autoid = manual_class_basepath,
cruise = cruise, dayhours = dh)Section 5: Data Processing
This is the main chunk of coding required to generate data products. Data processing step does not require image copying (Section 3) or manual re-classification (Section 4) steps. If these steps were taken, the aid and aidmeas files generated from manual re-classification, and integrated into the directory structure as specified in Section 4, are used as inputs. The following is a walk-through of the data processing step from a DFO field mission (i.e. mission COR2019002) in the southern Gulf of St. Lawrence in 2019. First, all libraries should be loaded. The processing environment, described in Section 2.4 should be loaded.
##### PROCESSING ---------------------------------------------------------
library(vprr)
#### FILE PATHS & SETTINGS ------------------------------------------------
# loads processing environment specific to user
load('COR2019002_env.RData')CTD data (including data from other environmental sensors) are loaded
in using vprr::vpr_ctd_read(). During CTD data read in, a
seawater density variable sigmaT is derived using the
function oce::swSigmaT, and depth (in meters)
is derived from pressure using the function oce::swDepth.
For more information on the oce package, see
dankelley/oce on GitHub.
#### READ CTD DATA --------------------------------------------------------
ctd_files <- list.files(castdir, pattern = '.dat', full.names = TRUE)
ctd_dat_combine <- vpr_ctd_read(
ctd_files,
station_of_interest,
col_list = c(
"time_ms",
"conductivity",
"temperature",
"pressure",
"salinity",
"reserved1_mV",
"FLNTU1_mV",
"FLNTU2_mV",
"reserved2_mV",
"pitch_degrees",
"roll_degrees",
"image_number"
)
)The aid (and aidmeas) files, which reflect manual classification (if used, see Section 4), are then found
##### FIND VPR DATA FILES ---------------------------------------------
# find aid files
auto_id_path <- list.files(new_autoid, full.names = TRUE)
# Path to aid for each category
aid_path <- paste0(auto_id_path, '/aid/')
# AUTO ID FILES
aid_file_list <- list()
for (i in 1:length(dh)) {
aid_file_list[[i]] <-
list.files(aid_path, pattern = dh[[i]], full.names = TRUE)
}
aid_file_list_all <- unlist(aid_file_list)
remove(aid_file_list, aid_path) # tidy up environment
# Path to aidmeas for each category
aidmeas_path <- paste0(auto_id_path, '/aidmea/')
# AUTO ID (MEASUREMENT) FILES
aidmea_file_list <- list()
for (i in 1:length(dh)) {
aidmea_file_list[[i]] <-
list.files(aidmeas_path, pattern = dh[[i]], full.names = TRUE)
}
aidmea_file_list_all <- unlist(aidmea_file_list)
remove(aidmea_file_list, aidmeas_path) # tidy up environmentaid (and aidmeas) files are read in using
vprr::vpr_autoid_read().
##### READ ROI DATA -----------------------------------------------------
roi_dat_combine <- vpr_autoid_read(
file_list_aid = aid_file_list_all,
export = 'aid',
station_of_interest = station_of_interest,
opticalSetting = opticalSetting,
categories = categories
)
#### READ MEASURMENT DATA -----------------------------------------------
meas_dat_combine <- vpr_autoid_read(
file_list_aid = aid_file_list_all,
file_list_aidmeas = aidmea_file_list_all,
export = 'aidmeas',
station_of_interest = station_of_interest,
opticalSetting = opticalSetting,
categories = categories
)Next, CTD and aid data are merged to create a data frame describing
both environmental variables (e.g., temperature, salinity) and
classified images. The function used is
vprr::vpr_ctdroi_merge().
##### MERGE CTD AND ROI DATA ------------------------------------------
ctd_roi_merge <- vpr_ctdroi_merge(ctd_dat_combine, roi_dat_combine)Before final export of data products, the following variables are
added to the data frame: time in hours (time_hr) is calculated, and a
time stamp (ymdhms) with POSIXct signature in Y-M-D h:m:s format is
added using the function vpr_ctd_ymd.
##### CALCULATED VARS -------------------------------------------------
data <- ctd_roi_merge %>%
# arrange data by image number to avoid processing errors downstream
dplyr::arrange(., image_number) %>%
# add optional variable time_hr
dplyr::mutate(., time_hr = time_ms / 3.6e+06)
data <- vpr_ctd_ymd(data, year)Average plankton concentration and environmental variables (e.g., temperature, salinity, density, etc.) are then computed along the path of the VPR in depth bins. The width of the depth bin is set by the user. In each bin plankton concentration, C, is computed as follows for each classification category:
C= R⁄nVWhere, in each bin, R is the number of ROIs, n is the number of frames, and V is the image volume (constant). An oce CTD object is created using vprr::vpr_oce_create(). Then, bin-averaging is done using vprr::bin_cast().
##### BIN DATA AND DERIVE CONCENTRATION ---------------------------------
# create oce object
ctd_roi_oce <- vpr_oce_create(data)
# bin and calculate concentration for all category (combined)
vpr_depth_bin <- bin_cast(ctd_roi_oce = ctd_roi_oce,
binSize = binSize,
imageVolume = imageVolume)
# bin and calculate concentrations for each category
category_conc_n <- vpr_roi_concentration(data,
categories,
station_of_interest,
binSize,
imageVolume)
Measurement data can also be binned to match the resolution of ROI data.
#### BIN SIZE DATA -------------------------------------------------------
size_df_f <- vpr_ctdroisize_merge(data,
data_mea = meas_dat_combine,
category_of_interest = c("krill"))
size_df_b <- vpr_size_bin(size_df_f, bin_mea = 3)Finally, data are saved as RData and csv files for export and
plotting. Data are also saved as an oce object in order to
preserve both data and metadata in an efficient format. This example
shows gathering metadata from an object vpr_summary_st
obtained from an external csv file, but it could also be input
manually.
##### SAVE DATA --------------------------------------------------------
#Metadata (from csv)
vpr_summary <- read.csv('vpr_metadata_COR2019002.csv')
vpr_summary_st <- vpr_summary[vpr_summary$event == as.numeric(cast), ]
startlat <- unique(vpr_summary_st$latitudeStart)
stoplat <- unique(vpr_summary_st$latitudeStop)
startlon <- unique(vpr_summary_st$longitudeStart)
stoplon <- unique(vpr_summary_st$longitudeStop)
zstn <- unique(vpr_summary_st$soundingStart)
ddate <- unique(vpr_summary_st$dateStart)
tstart <- unique(vpr_summary_st$timeStart)
tend <- unique(vpr_summary_st$timeStop)
vpr_comment <- unique(vpr_summary_st$comment)
#Save file
oce_dat <- vpr_save(category_conc_n,
metadata = list('deploymentType' = 'vprProfile',
'waterDepth' = zstn,
'serialNumber' = 'DAVPR-00',
'latitudeStart' = startlat,
'latitudeStop' = stoplat,
'longitudeStart' = startlon,
'longitudeStop' = stoplon,
'castDate' = ddate,
'castStartTime' = tstart,
'castEndTime' = tend,
'processedBy' = 'J. Doe',
'opticalSetting' = opticalSetting,
'imageVolume' = imageVolume,
'comment' = vpr_comment))
# oce data and metadata object
save(file = paste0(savedir, '/oceData_', station,'.RData'),
oce_dat)
# Save RData files
# VPR and CTD data
save(file = paste0(savedir, '/stationData_', station,'.RData'),
data)
# binned data including measurements
save(file = paste0(savedir, '/bin_size_dat_', station_of_interest,'.RData'),
size_df_b)
# Write csv files
# VPR and CTD data with concentrations by taxa
write.csv(file = paste0(stdir, '/vpr_data_binned', station, '.csv'),
category_conc_n)
# measurement data
write.csv(file = paste0(stdir, '/vpr_meas', station_of_interest, '.csv'),
roimeas_dat_combine) Section 6: Disclaimer
The functions in vprr were created for a specific project and have not been tested on a broad range of field mission data. It is possible that deviations in data format and directory structure from that described herein may result in errors when using vprr. The vprr package was developed for the purpose of processing data collected during tow-yo VPR deployments and image classification. The purpose of this document is to provide a template for processing and visualizing VPR data that can be adapted by other users for their own objectives.
Appendix 1: Directory Structure
The directory structure required is described below
- C:/
-
data
-
cruise_name
-
autoid
- category
- aid
- aidmea
- image folders
- category
-
rois
- vprtow#
- day
- hour
- day
- vprtow#
-
trrois
- vprtow#
- day
- hour
- day
- vprtow#
-
-
-
This is your project directory, where your R scripts and work products will be stored:
- …
VPR_PROJECT
-
R
- R scripts/ workflows
-
new_autoid
category
aid
aidmea
-
manual_reclassification_record
day/hour
misclassified
reclassified
figures
station names (csv)
Appendix 2: Glossary
Aid files - Visual Plankton style file output text file, listing file path information for ROI’s of a specific classification group. The aid file may also include a column specifying the probability score associated with each ROI.
AidMeas files (AutoID measurements) - Visual Plankton style output text file, listing measurement data for ROI’s of a specific classification group. Unit is pixels and columns are ‘Perimeter’, ‘Area’, ‘width1’, ‘width2’, ‘width3’, ‘short_axis_length’, ‘long_axis_length’
Auto Deck - software which pulls plankton images from Video Plankton Recorder frames based on specific settings
Auto ID - The automated classification given to an image from a machine learning algorithm
AutoID files - Includes both Aid and AidMeas files as part of automated classifications
Classification category (category) - A defined group under which VPR images can be classified, often represents a taxonomic group (e.g. Krill), but can also be defined by image type (e.g. ‘bad_image_blurry’), or other (e.g. ‘marine_snow’), should be one continuous string (no spaces)
CTD - Conductivity, Temperature and depth sensor instrument
Day - Julian calendar day on which VPR data was collected (three digits)
Hour - Two digit hour (24 hour clock) describing time at which VPR data was collected
Image volume - The measured volume of water captured within a VPR image. It varies with optical setting and image segmentation settings in Autodeck software and. The image volume is derived is calculated from the VPR calibration file (unique to each instrument) and measured in cubic mm.
Optical Setting - A VPR camera setting controlling image magnification and field of view. Optical settings can be S0, S1, S2 or S3, where S0 has the greatest magnification and smallest image volume, and S3 has the least magnification and largest image volume.
ROI - Images (regions of interest) identified by Autodeck software within VPR frames
station - A named location, where the VPR was deployed
Tow-yo - A VPR deployment method where the VPR is towed behind a vessel while being raised and lowered through the water column in order to sample over both depth and distance
TRROIS - Training set of images used to train machine learning algorithm
vprtow# - A numeric code which is unique to each VPR deployment